
According to Christine L. Borgman (2012), “Four rationales for sharing data [exist], drawing examples from the sciences, social sciences, and humanities: (1) to reproduce or to verify research, (2) to make results of publicly funded research available to the public, (3) to enable others to ask new questions of extant data, and (4) to advance the state of research and innovation.” Data presentation, preservation, and its peer review are key issues in the publication process to ensure integrity.

What happens to all the data you collected when you graduate and leave the university? And when your funding finishes and you need to rely on core services? What if your boss leaves, who is responsible for maintaining the data?

Both journals and funding agencies employ peer review as a way to prioritize allocations, be it of publication or funding. A project written and submitted for consideration to a funding call must provide a plan on how data will be stored and managed, as a budget may be allocated to this portion of the project.
In research manuscripts, the data availability statement is a valuable link between a paper’s results and the supporting evidence. Peer reviewers will examine these and verify if they are written in accordance to journal requirements, both in cases of pre-submission review, and most strenuously during post-publication audits.
Let’s examine the most common variations of data availability statements:
1. Data available with the paper or supplementary information
Supplementary material is relevant material that is additional to the main article. It can be anything from tables to presentations, to video and audio files. These supplementary materials help with increasing the article’s online reach, since they are never behind a paywall. Funders are also able to identify clear links to data, making sure you meet your certain funding requirements.
For instance, the Journal of Medical Internet Research (JMIR) will publishMultimedia Appendices (MAs) at the end of a paper. Examples of what could be uploaded as an MA include questionnaires, datasets, videos or screencasts, a PowerPoint® file, tables too long for the body of the manuscript, PDF files showing multiple screenshots, files containing the source code of a computer program, or informed consent documents.
2. Data cannot be shared openly but are available upon request from authors
Have you been asked to make your questionnaire data available? What if it is sensitive information, that could somehow lead to the identification of an individual participant?
Reviewers can and will request access to data that is only accessible with a password or key, if that access is essential to their revision of the manuscript’s claims. Thus, even negative findings should always be reported, as they aid in the advancement of science. It is also paramount to address how missing data was addressed or managed, if any imputation or post-hoc analyses were done, and how the data were handled. Because a reviewer is in a privileged position, it is essential to keep the integrity of the process.
3. Data publicly available in a repository
The best option is always to share your data. Sharing data encourages reproducibility, reduces duplication, and allows for re-use and re-purposing. Sharing data is increasingly required by most funding agencies and many journals demand it as a prerequisite for publication. Thus, data repositories were established.
Data repositories create metadata and documentation to ensure that the data will be discoverable and intelligible to future researchers. Repositories also provide regular back-ups and may even migrate file formats to avoid digital obsolescence.
 Additionally, a curated repository provides value-added services that help to organize, preserve, and share your data.
Additionally, a curated repository provides value-added services that help to organize, preserve, and share your data.
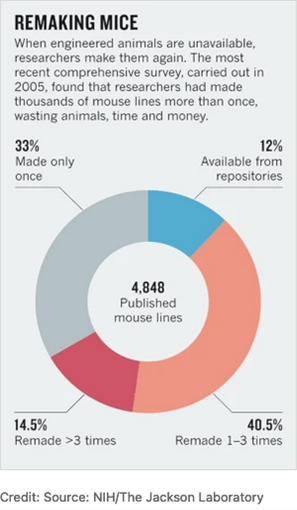
What about other resources that are produced during research? Well, there are repositories for those as well. As an example, the Mutant Mouse Resource & Research Centers (MMRRC) distributes and cryopreserves scientifically valuable, genetically engineered mouse strains and mouse embryonic stem cell lines, with potential value for the genetics and biomedical research community.
This stock center enabled adherence to rigor criteria established by the NIH and improved findability of specific mouse lines via RRIDs. The saved amount associated with remaking mouse lines or keeping them actively breeding in-house was estimated as billions, as mouse repositories increase reliability through curation, preservation, genetic quality control, and protection from pathogens.
Best practices in research data management were developed to address growing concerns over reproducibility and replicability. Developing a data management plan, creating data workflows, carefully recording protocols, and making calculations using open-source software can help to ensure that your work can be reproduced or replicated by others.
Data management
Research data are data that are used as primary sources to support technical or scientific enquiry, research, scholarship, or creative practice, and that are used as evidence in the research process and/or are commonly accepted in the research community as necessary to validate research findings and results.
Conversely, metadata are data about data. The cataloging system found in libraries is the prime example of metadata, which means that librarians at research institutions are the experts in this matter. Metadata elements grouped into sets designed for a specific purpose, e.g., for a specific domain or a particular type of information resource, are called metadata schemas. For example, Darwin Core (DwC) is used in the biological sciences to describe collections of biological objects or data and includes a glossary of terms intended to facilitate the sharing of information about biological diversity.

Adapted by Kasturi Kankonkar from a graphic by Jeff Moon Portage Network/Digital Research Alliance of Canada
The quality of metadata for the evaluation of the research data lifecycle is paramount. Structural metadata details how different datasets relate to one another or processing steps that have occurred (e.g., how pages are ordered to form chapters, versions of digital materials). Metadata can also be used for discovery and identification when it is descriptive – describing the context and content of datasets (e.g., title, author, keywords), but can comprise information needed to manage the resource and use the data (administrative metadata, such as software requirements, licensing, date of creation). Finally, statistical metadata or process data describes processes that collect and produce statistical data, while the quality of the statistical data is informed by reference metadata.
The European Code of Conduct for Research Integrity (ECCRI) states that researchers, research institutions, and organizations should:
- ensure appropriate stewardship, curation, and preservation of all data, metadata, protocols, code, software, and other research materials for a reasonable and clearly stated period.
- ensure that access to data is as open as possible, as closed as necessary, and where appropriate in line with the FAIR Principles (Findable, Accessible, Interoperable and Reusable) for data management.
- are transparent about how to access and gain permission to use data, metadata, protocols, code, software, and other research material.
- acknowledge data, meta-data, protocols, code, software, and other research materials as legitimate and citable products of research.
- ensure that any contracts or agreements relating to research results include equitable and fair provisions for the management of their use, ownership, and protection under intellectual property rights.
![]() Additionally, researchers should always inform research participants about how their data will be used, reused, accessed, stored, and deleted, in compliance with General Data Protection Regulation (GDPR).
Additionally, researchers should always inform research participants about how their data will be used, reused, accessed, stored, and deleted, in compliance with General Data Protection Regulation (GDPR).
Data management plans (DMP) can make everyday research work more efficient and effective, as they organize research procedures, enable data re-use, protect against costly data loss, meet ethical, privacy, and security requirements, and provide evidence of responsible research conduct. Crucially, DMP allow for “project memory” — sharing crucial information with team members, collaborators, etc.
• assigning responsibilities to research group members
• collecting data in a consistent and easily understood way
• following good file naming conventions
• using standard and non-proprietary file formats
• documenting your data thoroughly and consistently
• backing up data regularly
• making & following through with plans for storage of data for the long term
Want to learn more about Data and Peer Review? Click on below to listen to our recent Live Event!